9 min to read
SIEM Done Right:3stage RoadMap
It actually works!

Last week I got a situation that stuck me “Why does SIEM feel like it’s fighting against us instead of helping us”? It’s a fair question. Too many organisations jumps into SIEM implementation assuming they’ll flip a switch and suddenly have perfect visibility. I have been observing since my last 6 years in cybersecurity domain that most of the organisation approach towards SIEM deployment is completly wrong.They are simply adopting facing tools and doing partenership with fancy vendors. The reality?
We all knows or those who got chance to work within SOC might agree with me. Building an effective SIEM is like growing a garden-it takes time, care, planning and understanding what stage you’re in.
Lemme walk through the three stages of SIEM maturity I’ve seen in my working years with security teams and with SANS’s SIEM best practice approach.
Stage 1: New Deployment-Getting the basics right
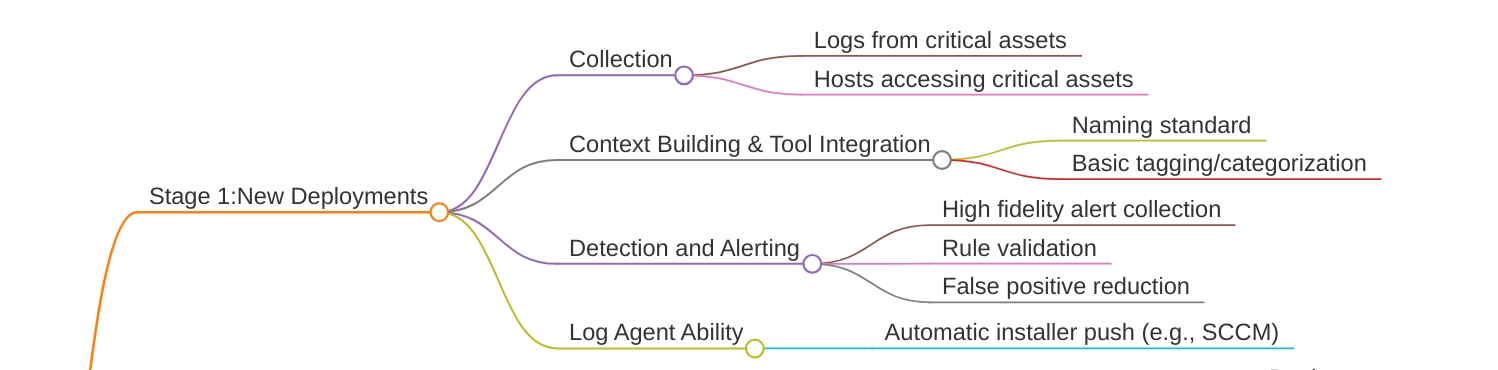
When you’re starting fresh with a SIEM, resit the urge to collect everything. I’ve seen too many teams drown in their own data because they tried to do too much, too fast. Your soc team might have onboarded SIEM like splunk, ELK stack or maybe it’s cloud native like Microsoft sentinel. Now your maangement is asking when they’ll see ROI and you’re drowing in alerts that might as well be written in ancient Greek.
What to focus on?
start small,Think Critical
Start with your crown jewels. What systems would make headlines if they got compromised? Your domain controllers, financial databases, customer data repositories - these are your priority targets. Don’t worry about collecting logs from every single workstation yet.
Here’s what I typically recommend for the first phase:
- Domain controllers (authentication events)
- Critical database servers (access and query logs)
- External-facing web servers (access logs and application events)
- Firewalls and perimeter security devices
- Key business applications
Priority 1: Domain Controllers (Security logs, System logs)
Priority 2: Critical application servers (Application logs, Security logs)
Priority 3: Jump boxes and admin workstations (Security logs, PowerShell logs)
Building Your Foundatio
This is where most teams mess up. They skip the boring organisational work and jump straight to writing detection rules. Don’t make this mistake.
Create a naming standard before you deploy anything. When you’re dealing with thousands of devices, “NYC-DC-01” is infinitely more useful than “Shubhendu’s Server.” Trust me on this one.
Your tagging strategy should be simple but consistent. Think about how you’ll search for things six months from now:
- Environment (Production, Staging, Development)
- Location (if you have multiple sites)
- Criticality (Critical, High, Medium, Low)
- Owner (which team is responsible)
Naming the best practice should tell a story e.g.:-
DC-NYC-PRIMARY instead of WIN-SRV-001
DB-CUSTOMER-PROD instead of SQL-BOX-02
Detection and Alerting
High Fidelity First
You’re goal isn’t to catch everything-it’s to catch the things that matter without burning out your team
| Alert Type | Description / Notes |
|---|---|
| Failed admin logins | More than 5 in 10 minutes |
| Service account lockouts | These should never happen |
| Off-hours admin activity | Define what “off-hours” means for your business |
| New admin account creation | Every single one should be investigated |
| Failed authentication attempts | Especially for admin accounts |
| New local administrator account creation | Should be flagged and reviewed |
| Successful logins from impossible locations | Indicates potential credential compromise |
| Antivirus detection alerts | May signal malware or suspicious behavior |
| Firewall blocks to critical servers | Could indicate attempted unauthorized access |
The False Positive Battle
Expect to spend 60% of your first three months tuning these alerts. That’s normal. Document every tuning decision - your future self will thank you.
Technical Requirements for Stage 1:
Log Agent Deployment
Keep it simple (KISS) approach
Windows: Use the built-in Windows Event Forwarding (WEF) if possible
Linux: Rsyslog or built-in syslog forwarding
Network devices: SIEM vendor’s universal forwarder
Deployment Method: Manual is fine at this stage. Yes, manual. You need to understand what you’re deploying before you automate it.Later use your existing software deployment tools like SCCM , Group Policy etc to push agents automatically. Since Manual installation doesn’t scale and creates gaps in coverage.
Retention: Start with 90 days of hot storage. You can always adjust later based on your needs and budget.
Alerting: Email notifications are fine initially. Focus on getting the detection logic right before you worry about fancy dashboards.
Stage 2: Established Deployments - Scaling Up Intelligently
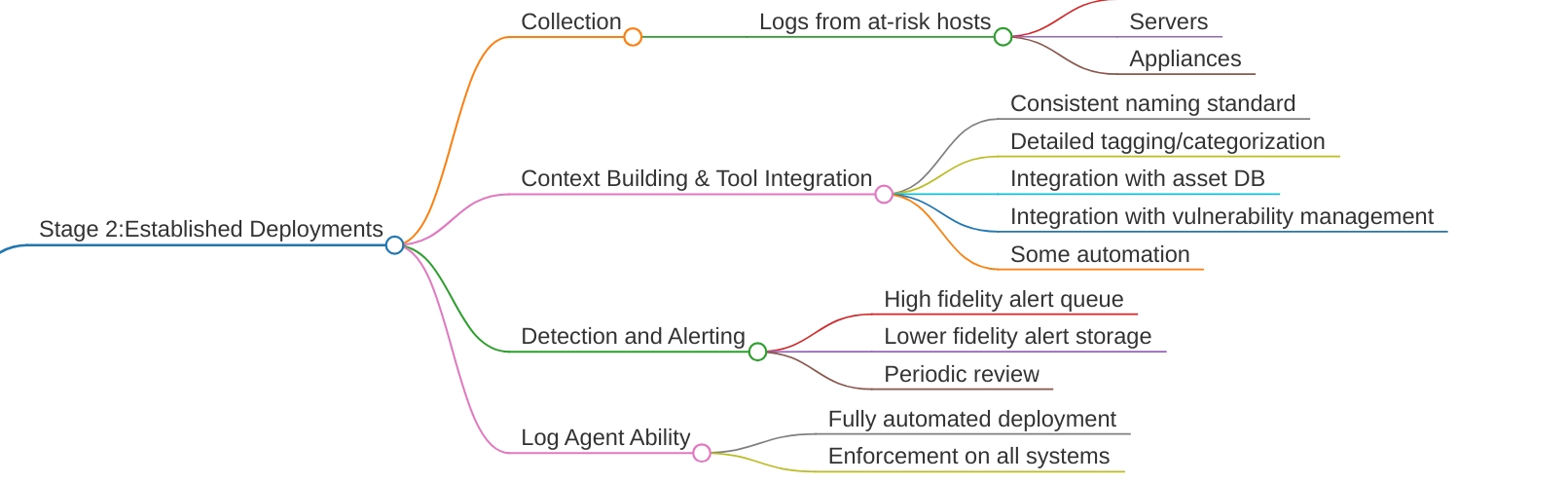
Once you’ve got your critical systems covered and your team is comfortable with the alert volume, it’s time to expand. But do it strategically.
Expanding Your Collection Now you can start collecting from riskier systems - the ones that might generate more noise but give you better visibility:
| Asset Type | Description / Notes |
|---|---|
| Domain Controllers | Include all, not just primary |
| Database Servers | Include development databases accessing production data |
| Web Servers & Application Servers | Ensure coverage of both front-end and back-end services |
| Network Appliances | Firewalls, proxies, load balancers |
| Desktop Computers | Prioritize privileged users |
| Application Servers | May be listed separately for emphasis |
| Network Appliances (duplicate) | Load balancers, proxies (already covered above—consider consolidating) |
| Cloud Infrastructure Logs | Include logs from cloud-native services and platforms |
The key is to expand gradually. Add one new log source at a time, tune it properly, then move to the next one.
Integration is Everything
This is where your SIEM starts becoming truly powerful. Start connecting it to other security tools:
Asset Knowledge Database Integration: Your SIEM should know which systems are critical, who owns them, and what they’re used for. When you get an alert from “192.168.1.100,” you should immediately see it’s the HR payroll server
Vulnerability Management Integration: When your SIEM knows that WEB-PROD-01 has unpatched critical vulnerabilities, that failed login alert suddenly becomes much more interesting.
Alert Queue Management
You now have two types of alerts:
-
High-fidelity alerts - These wake people up
-
Medium-fidelity alerts - These get reviewed during business hours
The Storage Strategy: Don’t delete the medium-fidelity stuff. Store it in a “warm” storage tier and review it weekly. You’ll find patterns that inform your high-fidelity rules.
Automated Deployment (Finally!)
- SCCM/Group Policy Deployment
Now you can start pushing agents automatically. But please, test in a lab environment first. I once saw an agent update take down half a hospital’s workstations because they didn’t test the new version.
Deployment Strategy:
-
Test group (5-10 systems)
-
Pilot group (50-100 systems)
-
Phased rollout (25% per week)
-
Full deployment
Stage 3: Mature Deployments - Advanced Detection and Response
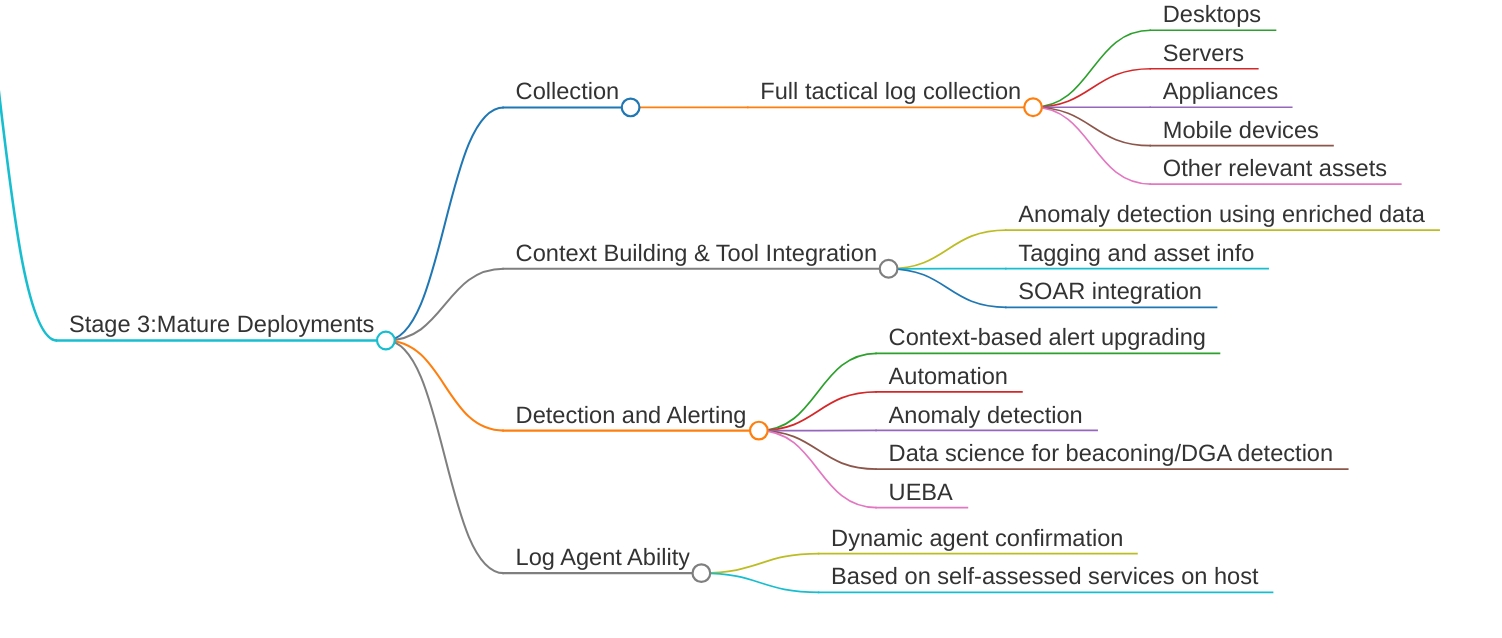
This is where the magic happens. Your SIEM transforms from a reactive tool into a proactive threat hunting platform.At this stage, you’re collecting logs from everything that matters:
| Asset Type | Description / Notes |
|---|---|
| Desktops | Yes, all of them—ensure full endpoint coverage |
| Servers | Includes all production and non-production servers |
| Mobile Device Management (MDM) | Systems managing mobile endpoints; key for policy enforcement and log collection |
| Mobile Devices | Covered via MDM integration; includes smartphones and tablets |
| Cloud Services | AWS CloudTrail, Office 365, Azure, GCP—focus on audit, access, and activity logs |
| Cloud Applications & Infrastructure | SaaS platforms and IaaS/PaaS environments; include identity, storage, compute logs |
| IoT Devices | Printers, security cameras, HVAC systems—often overlooked but critical for visibility |
| Operational Technology (OT) | Industrial control systems, building automation—log collection may require custom setups |
The Challenge: You’re now ingesting 10TB+ per day. Your old parsing rules don’t scale. Now you can start leveraging the advanced features that seemed like science fiction in Stage 1:
Anomaly Detection with Asset Intelligence:-
now your SIEM knows what normal looks like for each user and device,When Shubhendu from Seurity team suddently start accessing HR Database at 3 am, your soc team will get alert.
Behavioral Analytics (UEBA): Track how users and entities behave over time. Detect insider threats, compromised accounts, and advanced persistent threats that traditional signature-based detection misses.
Machine Learning for Threat Detection:
- Beaconing detection: Identify command and control communication patterns
- DGA (Domain Generation Algorithm) detection: Catch malware generating random domains
- Lateral movement detection: Track attackers moving through your network
SOAR(Security Orchestration and Automated Response) Integration
orchestrate your entire security response. When a high-severity alert fires:
- Automatically gather additional context
- Check threat intelligence feeds
- Create an incident ticket
- Potentially isolate the affected system
- Notify the appropriate response team
Dynamic and Self-Healing
Your monitoring infrastructure should adapt automatically. New services get discovered and monitored. Agents self-update and self-heal. The system continuously optimizes itself based on the threats it’s seeing.
Shubhendu’s Tips:
- Start Small, Think Big
- Don’t try to jump straight to Stage 3. Each stage builds on the previous one. The organizational and technical foundations you build in Stage 1 are what make the advanced capabilities in Stage 3 possible.
- Budget Realistically
- A mature SIEM is expensive - not just in licensing costs, but in staff time, training, and infrastructure. Plan for this from the beginning.
- Focus on Your Use Cases
-
Every organization is different. Don’t copy past SIEM architecture from online available data, A financial services company has different monitoring needs than a manufacturing plant. Tailor your approach to your specific threats and compliance requirements.
- Measure What Matters
Track metrics that actually matter:
- Mean time to detection (MTTD)
- Mean time to response (MTTR)
- False positive rate
- Alert closure rate
- Analyst satisfaction (yes, this matters!)
Don’t get caught up in vanity metrics like “events per second”(EPS) that don’t correlate with security outcomes.The best SIEM in the world is useless if your analysts can’t use it effectively. Invest in training and usable interfaces.Please don’t treat your SIEM as “Set and Forget”, keep tuning, keep learning, keep troubleshooting!


Comments