5 min to read
Stop Fighting Local LLMs:Docker Just fixed the Mess
Docker Model Runner

If you’re like me and have been wrestling with running LLMs locally for development, Docker just dropped something that might change your workflow completely.
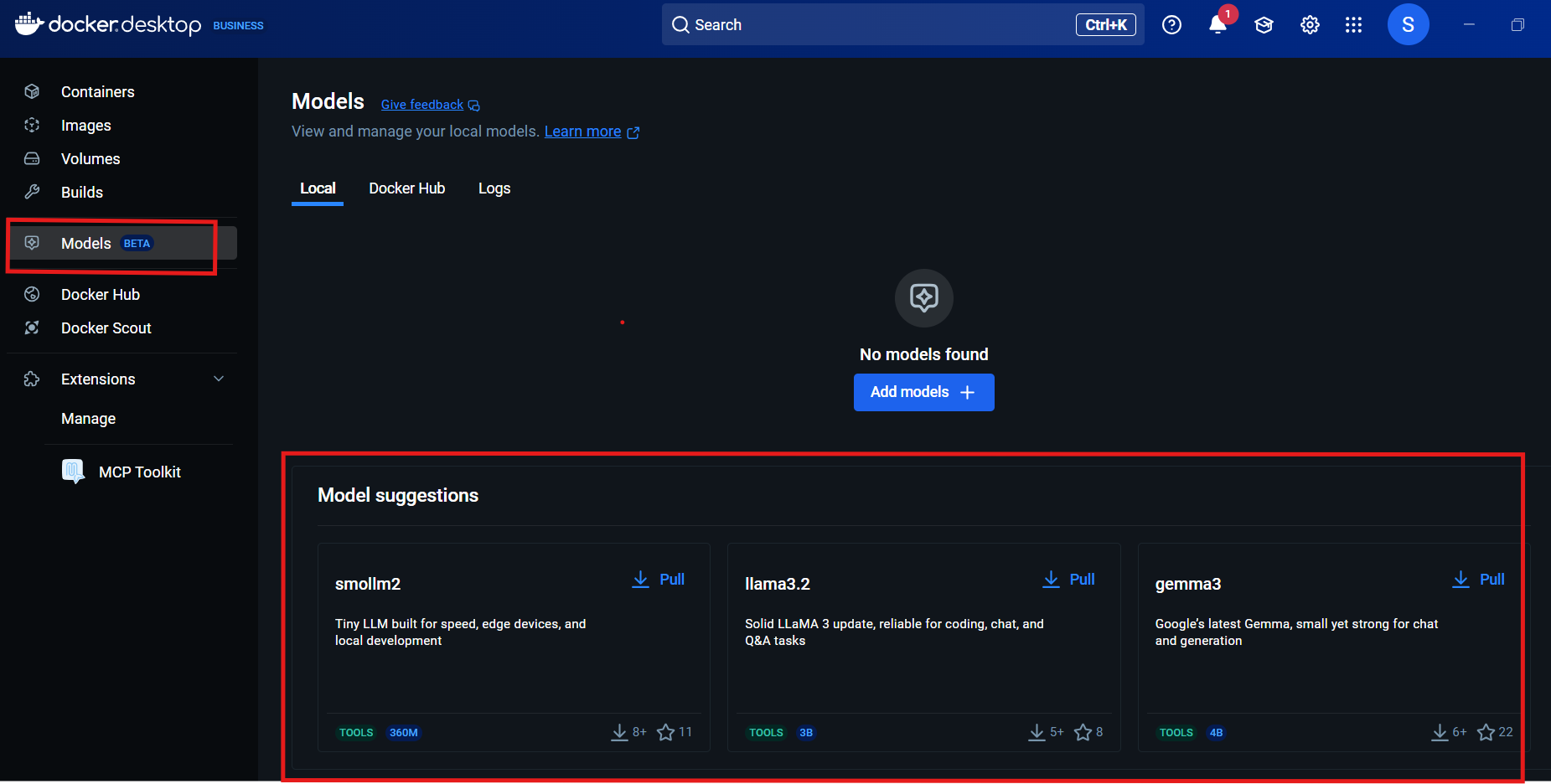 The new “Models” tab you see in Docker Desktop isn’t just another UI addition—it’s part of Docker Model Runner, a beta feature that’s currently shaking up how we work with AI models locally.
The new “Models” tab you see in Docker Desktop isn’t just another UI addition—it’s part of Docker Model Runner, a beta feature that’s currently shaking up how we work with AI models locally.
What Exactly Is This Thing?
Docker Model Runner makes it easier for developers to run AI models locally. No extra setup, no jumping between tools, and no need to wrangle infrastructure.
Think of it as Docker’s attempt to solve the mess that is local LLM development. Instead of dealing with Python environments, CUDA installations, or whatever tool-of-the-week the AI community is obsessing over, you just use Docker commands you already know.
The key insight here is simple: Docker Model Runner is designed to make AI model execution as simple as running a container. But here’s the plot twist—the models don’t actually run in containers.
The Technical Reality (And Why It Matters)
Here’s where things get interesting from a technical standpoint. When you run:
docker model run ai/smollm2:360M-Q4_K_M "Tell me about whales"
You might expect Docker to spin up a container like it usually does. But it doesn’t. In the case of the Model Runner, this command won’t spin up any kind of container. Instead, it’ll call an Inference Server API endpoint, hosted by the Model Runner through Docker Desktop, and provide an OpenAI compatible API.
Under the hood, Docker is running an inference engine built on top of llama.cpp and accessible through the familiar OpenAI API. The critical difference? By using host-based execution, we avoid the performance limitations of running models inside virtual machines.
This means your LLM is running directly on your Mac’s metal. The performance difference is significant.
Why Should You Care?
1.Performance That Actually Works
If you’ve tried running large models in Docker containers before, you know the pain. Virtual machine overhead kills inference speed. To avoid the typical performance overhead of virtual machines, Docker Model Runner uses host-based execution. This means models run directly on Apple Silicon and take advantage of GPU acceleration.
Translation: Your models run fast enough to actually be useful during development.
2.Familiar Workflow, No Learning Curve
Remember when Docker made containers easy by giving us docker run? They’re doing the same thing for AI models:
docker model pull ai/gemma3:2B
docker model list
docker model run ai/gemma3:2B "Write a function to reverse a string"
If you know Docker, you already know Docker Model Runner.
3.Standard Model Distribution
This is probably the biggest win. With Docker Model Runner, we package models as OCI Artifacts, an open standard that allows you to distribute and version them through the same registries and workflows you already use for containers.
No more downloading random files from HuggingFace. No more managing model versions manually. Your models are now first-class citizens in your CI/CD pipeline.
How This Differs from Regular Docker + LLM Setups?
Let’s be honest about the alternatives and why they suck:
Traditional Docker Approach
# The old way - run everything in a container
docker run -it --gpus all -p 8000:8000 \
-v $(pwd)/models:/models \
some-llm-image:latest
Problems:
- GPU passthrough is a nightmare
- Model files need to be mounted manually
- VM overhead kills performance
- Complex networking setup
Docker Model Runner Approach
# The new way
docker model run ai/llama3.3:8B "Generate code"
Benefits:
- GPU acceleration on Apple silicon by executing the inference engine directly as a host process
- Models are cached and reused automatically
- OpenAI-compatible API endpoint at
http://model-runner.docker.internal/engines/v1 - Zero configuration required
Real-World Usage Patterns
Development Workflow
# Pull a model once
docker model pull ai/smollm2:360M-Q4_K_M
# Use it from your app code
curl http://model-runner.docker.internal/engines/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model": "ai/smollm2", "messages": [{"role": "user", "content": "Debug this Python function"}]}'
Integration with Existing Apps
Any code that works with OpenAI’s API can work with Model Runner. Just change the base URL:
from openai import OpenAI
# Point to local Model Runner instead of OpenAI
client = OpenAI(
base_url="http://model-runner.docker.internal/engines/v1",
api_key="not-needed-for-local"
)
response = client.chat.completions.create(
model="ai/smollm2",
messages=[{"role": "user", "content": "Hello!"}]
)
Host Access
If you want to access the API from outside Docker (like from your IDE):
# Enable TCP access
docker desktop enable model-runner --tcp 12434
# Now you can hit localhost
curl http://localhost:12434/engines/v1/models
The Bigger Picture
Docker isn’t just adding a feature here. They’re trying to solve the fundamental mess that is AI development tooling. Developers are often forced to manually integrate multiple tools, configure environments, and manage models separately from container workflows.
The vision is clear: make AI models as easy to use as container images. Pull, run, version, deploy—using the same tools and workflows you already know.
Should You Use It?
If you’re on Mac and doing AI development, absolutely try it. The setup is trivial and the performance is genuinely good. Even in beta, it’s already more reliable than most local LLM setups I’ve dealt with.
If you’re on Windows Docker Desktop vs4.41 is available on Windows + NVIDIA GPU and Latest Docker release will be having windows + Qualcomm support as well. In upcoming release Docker Desktop gonna target all eco system with awesome Model Runner feature.
Keep eyes on the official docs for the latest features.


Comments